Abstract
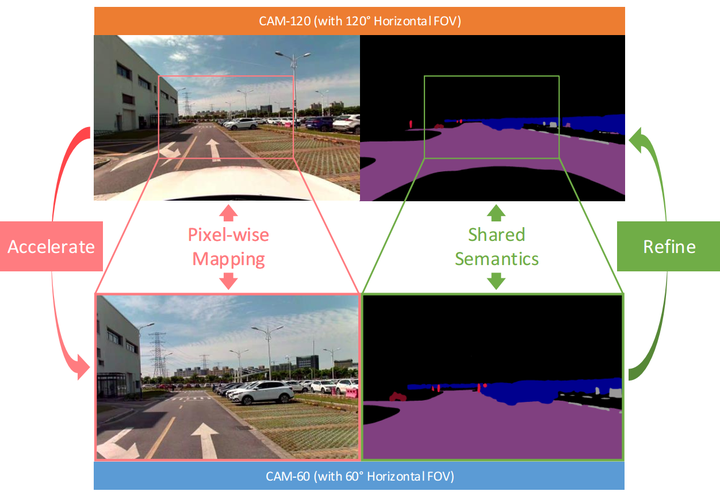
Real-time scene parsing is a fundamental feature for autonomous driving vehicles with multiple cameras. Comparing with traditional methods which individually process the frames from each camera, in this letter we demonstrate that sharing semantics between cameras with overlapped views can boost the parsing performance. Our framework is based on a deep neural network for semantic segmentation but with two kinds of additional modules for sharing and fusing semantics. On one hand, a semantics sharing module is designed to establish the pixel-wise mapping between the input image pair. Features as well as semantics are shared by the map to reduce duplicated workload which leads to more efficient computation. On the other hand, feature fusion modules are designed to combine different modal of semantic features, which learns to leverage the information from both inputs for better results. To evaluate the effectiveness of the proposed framework, we collect a new dataset with a dual-camera vision system for driving scene parsing. Experimental results show that our network outperforms the baseline method on the parsing accuracy with comparable computations.